
La scelta del RAID più opportuno in base al workload con cui verrà utilizzato l’array di dischi è una scelta che deve trovare il miglior connubio tra performance, tolleranza ai guasti e spazio disponibile
In questo post analizzerò le performance di scrittura dei RAID 10, RAID 50 e RAID 5 ovvero dei RAID che normalmente vengono presi in considerazione nel caso di workload che prevedono un elevato IOPS di scrittura di grandi dimensioni, ovvero un workload tipico per scenari di server di database OLTP (Online Transaction Processing) o di server di videosorveglianza.
I test sono stati eseguiti su un server HP DL380 Gen 10 Plus con 2 processori Intel Xeon Gold 633Y 2.40Ghz (48 core in totale e 96 processori logici), 256 GB di RAM e un controller HPE SR932i-p Gen 10+.
L’array di test aveva le seguenti caratteristiche sia per il RAID 10 che per RAID 50 e il RAID 5:
- Stripe da 512KiB:
- 22 HDD da 2.4 TB SAS 512e HPE EG002400JWJNN da 10K Rpm
Ovviamente come riportato in Selecting the right RAID type for your IT infrastructure | HPE SR Gen10 Plus Controller User Guide il RAID 10 offre le performance migliori e la maggiore tolleranza ai guasti, mentre il RAID 50 e il RAID 5 offrono un maggior spazio disponibile.
Di seguito un estratto da Selecting RAID for write performance | HPE SR Gen10 Plus Controller User Guide:
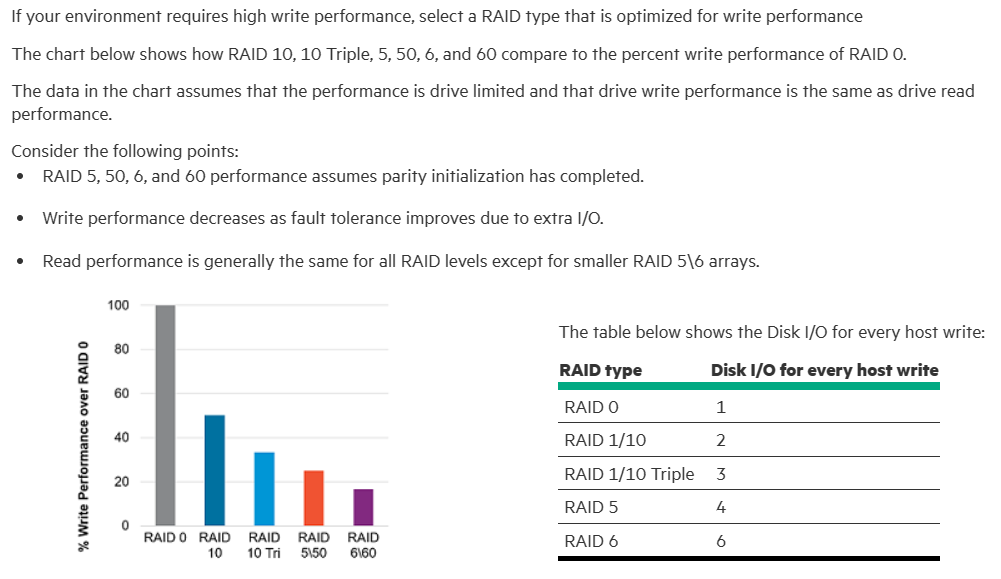
Di seguito un estratto da Selecting RAID for fault tolerance | HPE SR Gen10 Plus Controller User Guide:
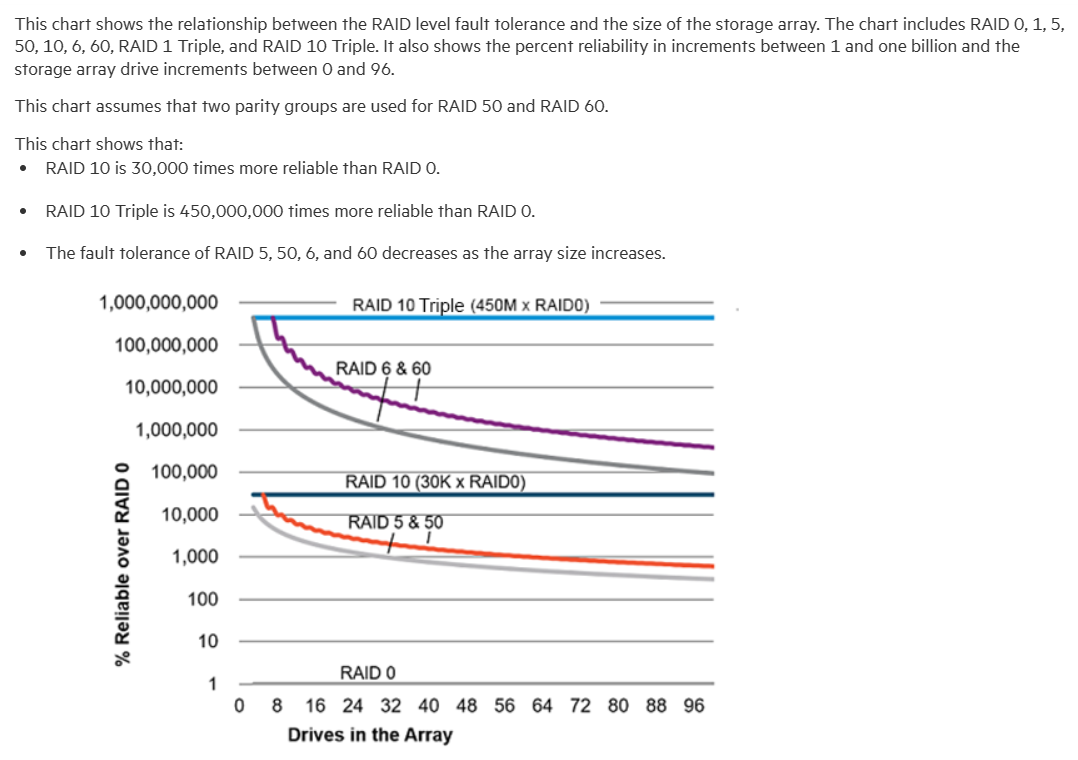
Di seguito un estratto da Selecting RAID for usable capacity | HPE SR Gen10 Plus Controller User Guide:
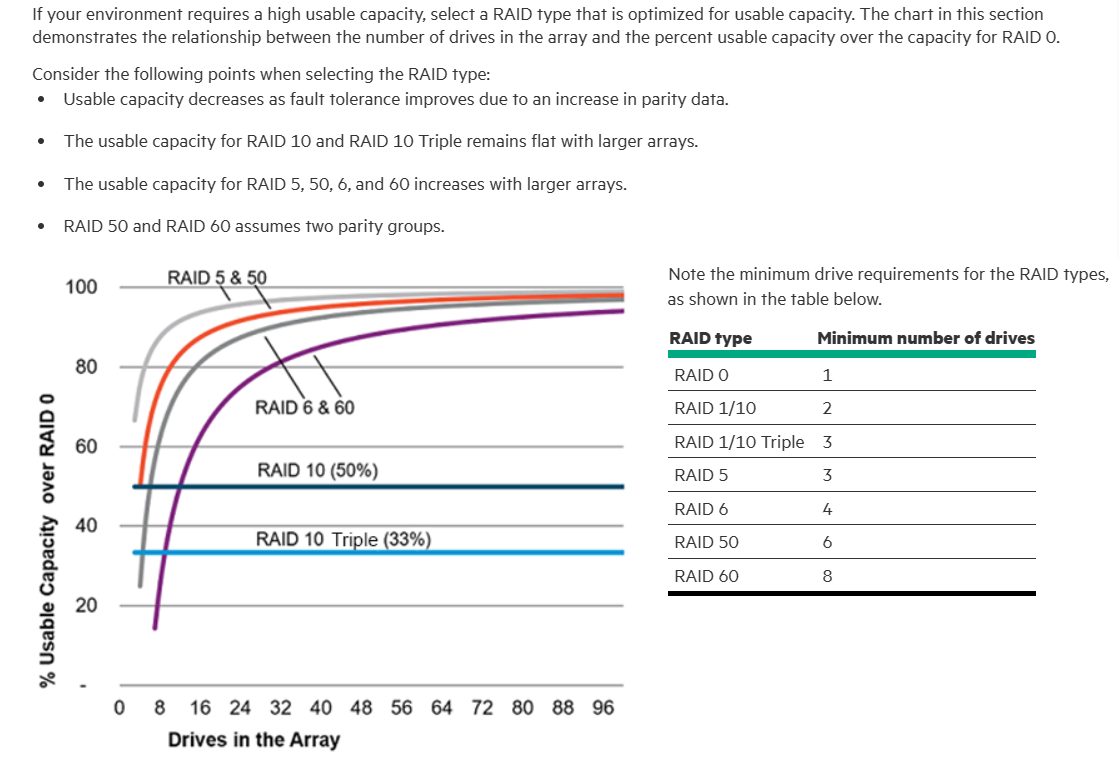
Per eseguire i test ho utilizzato l’utility a riga di comando DISKSPD uno strumento da riga di comando per la generazione di I/O per il micro-benchmarking. E’ possibile scaricare DISKSPD dal repository GitHub https://github.com/microsoft/diskspd per l’utilizzo si faccia rifermento ai seguenti:
- Use DISKSPD to test workload storage performance – Azure Stack HCI | Microsoft Learn
- Benchmark your application on Azure Disk Storage – Azure Virtual Machines | Microsoft Learn
- Command line and parameters · microsoft/diskspd Wiki (github.com)
- Sample command lines · microsoft/diskspd Wiki (github.com)
- Analyzing test results · microsoft/diskspd Wiki (github.com)
- Customizing tests · microsoft/diskspd Wiki (github.com)
- Test Storage Spaces Performance Using Synthetic Workloads in Windows Server | Microsoft Learn
- DiskSpd Workload Profiles | Virtual Client Platform (microsoft.github.io)
Per eseguire il test ho utilizzato il seguente comando che esegue un carico sintetico di scrittura massiva, che potrebbe essere quello tipico di un sistema di videosorveglianza o di un database OLTP (Online Transaction Processing):
diskspd.exe -c200G -b64K -r64K -W60 -d300 -F48 -o10 -Sh -w100 -D -L -Rtext R:\f1.dat R:\f2.dat R:\f3.dat R:\f4.dat R:\f5.dat
Di seguito il significato dei parametri utilizzati:
- c200G Crea (o ricrea) un file di test da 200 GB per ridurre al minimo la memorizzazione nella cache
- b64K Imposta una dimensione del blocco di 64K
- r64K Imposta un test di I/O casuale allineato alle dimensioni di 64K
- W60 Specifica la durata del tempo di riscaldamento in secondi prima dell’avvio delle misurazioni
- d180 Durata del test in secondi, escluso il riscaldamento
- F48 Imposta un totale di 48 threads (# core logici / 2 a riguardo si veda DiskSpd Workload Profiles | Virtual Client Platform (microsoft.github.io))
- o10 Numero di richieste di I/O in sospeso per ogni thread (profondità della coda), 1 = synchronous I/O (512 / # threads a riguardo si veda DiskSpd Workload Profiles | Virtual Client Platform (microsoft.github.io))
- -Sh Disabilita la memorizzazione nella cache di scrittura software e hardware (equivalente a -Suw)
- w100 Percentuale di richieste di scrittura (default = 0 che corrisponde al 100% di operazioni di lettura)
- D Acquisisce le statistiche delle operazioni di I/O al secondo
- L Misura le statistiche di latenza
- Rtext Visualizza l’ouput in formato testo
- R:\f1.dat R:\f2.dat R:\f3.dat R:\f4.dat R:\f5.dat Esegue il test sul drive R: tramite 5 file
DiskSpd fornirà vari dati tra cui i valori di MiB/s, I/O per s e AvgLat che permetteranno di comprendere le performance dell’array a seconda del RAID impostato. Il valore AvgLat si riferisce alla latenza media in millisecondi delle operazioni eseguite che sono il numero file * il numero di thread * il numero di richieste di I/O in sospeso quindi nell’esempio 5*48*10=2.400, questo significa che il valore della latenza media della singola operazione di scrittura è AvgLat/2400.
Di seguito i dati rilevati da cui si può notare come potavamo che il RAID 10 ha una performance pari a circa il doppio del RAID 5 e più del doppio del RAID 50. Sebbene con un workload di tipo random write massivo il RAID 5 abbia performance di poco superi al RAID 50 (a riguardo si vedano anche le mie considerazioni nel post Considerazioni per la scelta del RAID corretto – DevAdmin Blog ), si noti però che in caso di rebuild il RAID 5 ha un calo drastico delle performance al contrario del RAID 50.
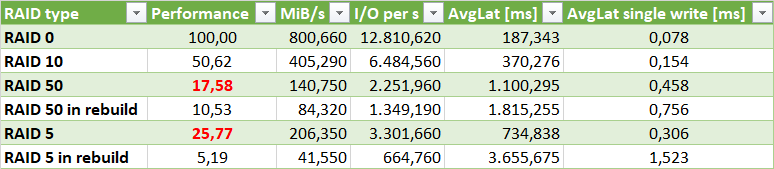
Inoltre si tenga presente che il RAID 5 non va utilizzato con un numero elevato di dischi in quanto si corre il rischio che più dischi vadano in fault contemporaneamente o che altri dischi vadano in fault durante la rebuild, infatti se si prova a creare un RAID 5 con 22 HDD l’HPE Smart Storage Administrator riporta il seguente warning:
Questa unità logica sarà creata su un array con più di 14 unità fisiche. Non è consigliabile espandere l’array o creare unità logiche aggiuntive su questo array. L’utilizzo di più di 14 unità in un array con RAID 5 aumenta la probabilità di guasti a più unità. Un guasto di due o più unità comporterà la perdita di tutti i dati sull’unità logica. NOTA: l’utilizzo da 14 a 28 unità rappresenta un rischio medio, mentre l’utilizzo di più di 29 unità su un array è un rischio elevato. Per ridurre il rischio di guasti a più unità, assegnare all’array un ricambio online e utilizzare la schermata delle impostazioni del controller per impostare la priorità di ricostruzione su alta. Tuttavia ciò non ridurrà il rischio di utilizzare più del numero di unità consigliato per creare un’unica unità logica RAID 5, mentre si dovrebbe ridurre il rischio associato a tale decisione. Scegliendo Sì, si continuerà con il RAID selezionato.
Concludendo se la scelta del RAID 10 è troppo onerosa a causa del fatto che si perde la metà della capacità di archiviazione disponibile valutare al posto un RAID 50, in quanto le sue performance non calano drasticamente in caso di rebuild al contrario del RAID 5.
1 commento su “Confronto performance di scrittura tra RAID 10, RAID 50 e RAID 5”